2022. 3. 19. 12:07ㆍAI/Big data
- 목차
https://colab.research.google.com/에 train.csv와 test.csv를 upload
data load
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')독립변수와 종속변수 구분
종속변수 = 목적 변수
train_x = train.drop(['survived'], axis=1)
train_y = train['survived']test data는 독립변수만 있음
test_x = test.copy()feature extraction
학습 가능한 feature로 만듦
학습은 GBDT 사용
- GBDT를 사용하려면, one-hot encoding 필요 (label encoding)
from sklearn.preprocessing import LabelEncoder불필요한 passenger id를 제거
train_x = train_x.drop(['PassengerId'], axis=1)
test_x = test_x.drop(['PassengerId'], axis=1)불필요한 Name, Ticket, Cabin 제거
train_x = train_x.drop(['Name', 'Ticket', 'Cabin'], axis=1)
test_x = test_x.drop(['Name', 'Ticket', 'Cabin'], axis=1)label encoding
- sex와 Embarked에 대해 label encoding
- 결측 데이터 확인
train_x['Sex'].isna() 0 False
1 False
2 False
3 False
4 False
...
886 False
887 False
888 False
889 False
890 False
Name: Sex, Length: 891, dtype: booltrain_x['Sex'].isna().sum() 0결측 데이터는 없음
이제 'Sex'에 대해서 'male', 'female'을 0과 1로 label encoding 수행
le = LabelEncoder()
le.fit(train_x['Sex'].fillna('NA'))
train_x['Sex'] = le.transform(train_x['Sex'].fillna('NA'))
test_x['Sex'] = le.transform(test_x['Sex'].fillna('NA'))label encoding 변환 결과
train_x['Sex']0 1
1 0
2 0
3 0
4 1
..
886 1
887 0
888 0
889 1
890 1
Name: Sex, Length: 891, dtype: int64'Embarked'에 대해서도 label encoding 수행
le = LabelEncoder()
le.fit(train_x['Embarked'].fillna('NA'))
train_x['Embarked'] = le.transform(train_x['Embarked'].fillna('NA'))
test_x['Embarked'] = le.transform(test_x['Embarked'].fillna('NA'))0 3
1 0
2 3
3 3
4 3
..
886 3
887 3
888 3
889 0
890 2
Name: Embarked, Length: 891, dtype: int64모델 구축
정형 data의 경우 GBDT 모델이 효과적임
GBDT 중 하나인 xgboost
모델 생성 및 학습
from xgboost import XGBClassifier
model = XGBClassifier(n_estimators=20, random_state=71, use_label_encoder=False)
model.fit(train_x, train_y) XGBClassifier(n_estimators=20, random_state=71, use_label_encoder=False)예측
pred = model.predict_proba(test_x) array([[0.86473066, 0.13526936],
[0.513669 , 0.48633102],
[0.82747805, 0.17252192],
[0.82747805, 0.17252192],
[0.51461303, 0.48538697],각 사람들의 비생존, 생존의 확률을 보여줌
첫 번째 사람의 경우 생존 확률은 13% 정도임
생존 확률만 보고 싶다면,
pred = model.predict_proba(test_x)[:, 1] array([0.13526936, 0.48633102, 0.17252192, 0.17252192, 0.48538697,
0.17252192, 0.6266853 , 0.25083348, 0.6266853 , 0.17252192,
0.13526936, 0.2509813 , 0.90446395, 0.17252192, 0.90446395,
...생존 확률이 0.5 이상인 경우는 1로, 아닌 경우는 0으로 치환
pred_label = np.where(pred > 0.5, 1, 0)제출 파일 생성
submission = pd.DataFrame({'PassengerId': test['PassengerId'], 'Survived': pred_label}) PassengerId Survived
0 892 0
1 893 0
2 894 0
3 895 0
4 896 0
... ... ...
413 1305 0
414 1306 1
415 1307 0
416 1308 0
417 1309 0
418 rows × 2 columnssubmission.to_csv('submission.csv', index=False)모델 평가
validation: 평가용 데이터로 예측 성능을 평가
cross-validation (교차 검증)
block 별 검증
전체 data set을 n 등분하여
n 개중 하나를 validation data로 사용
각 fold 별로,
- 이를 0부터 n - 1까지 이동하면서 validation으로 선택
- 각 fold의 validation data의 예측 점수를 합하여 평가
logloss
- 이진 분류의 평가시 logloss를 사용
- 분류 문제의 대표적인 평가지표
- cross entropy라고 부름
- log 손실이 낮을 수록 좋은 지표
logloss 계산
- label (1, 0) 과 예측 확률을 가지고 loss를 계산
- 양성의 예측 확률만 계산
- 양성에 대해 높은 양성 예측 -> 높은 예측 확률
- 음성에 대해 낮은 양성 예측 -> 높은 예측 확률
- 이들 loss를 평균
- 수식에 -1을 앞에 곱함
- 이는 실제값 예측 확률에 log를 취함 (음수가 나오니) 부호를 반전
- 수식에 -1을 앞에 곱함
from sklearn.metrics import log_loss, accuracy_score
from sklearn.model_selection import KFold
scores_accuracy = []
scores_logloss = []
kf = KFold(n_splits=4, shuffle=True, random_state=71)for tr_idx, va_idx in kf.split(train_x):
tr_x, va_x = train_x.iloc[tr_idx], train_x.iloc[va_idx]
tr_y, va_y = train_y.iloc[tr_idx], train_y.iloc[va_idx]
model = XGBClassifier(n_estimators=20, random_state=71, use_label_encoder=False)
model.fit(tr_x, tr_y)
va_pred = model.predict_proba(va_x)[:, 1]
logloss = log_loss(va_y, va_pred)
accuracy = accuracy_score(va_y, va_pred > 0.5)
scores_logloss.append(logloss)
scores_accuracy.append(accuracy)
logloss = np.mean(scores_logloss)
accuracy = np.mean(scores_accuracy)
print(f'logloss: {logloss:.4f}, accuracy: {accuracy:.4f}')- tr_x, va_x = train_x.iloc[tr_idx], train_x.iloc[va_idx]
- train과 valid로 사용할 index들을 iloc에 넣어 이에대한 row들을 train_x와 valid_x로 분리
- tr_y, va_y = train_y.iloc[tr_idx], train_y.iloc[va_idx]
- 마찬가지로 종속변수 y 역시 train과 valid로 분리
- model = XGBClassifier(n_estimators=20, random_state=71, use_label_encoder=False)
- 모델을 만든 후,
- model.fit(tr_x, tr_y)
- train data로 학습
- va_pred = model.predict_proba(va_x)[:, 1]
- valid data에 대해 예측 수행
- logloss = log_loss(va_y, va_pred)
- 예측한 결과와 실제 결과의 loss를 logloss로 계산
- accuracy = accuracy_score(va_y, va_pred > 0.5)
- 이번에는 accuracy_score로 계산
- logloss 값과 accuracy를 저장하고,
- logloss = np.mean(scores_logloss)
- accuracy = np.mean(scores_accuracy)
- 산술평균을 계산
logloss: 0.4270, accuracy: 0.8148
logloss
모델 성능 평가 지표
확률에 log를 취하여 이를 panalty로 사용
100%의 확률로 예측 시 -log(1.0) = 0 (0의 panalty)
-log(0.8) = 0.2231, -log(0.6) = 0.5108... 낮은 확률일수록 기하급수적으로 높은 panalty를 적용
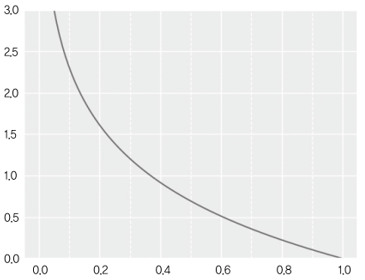
0.4270의 loss는 대략 70%의 예측 확률을 의미함을 알 수 있다.
accuracy
- accuracy
- 교차 검증 정확도
- 예측이 정확한 비율
accuracy = (TP + TN) / (TP + TN + FP + FN)
accuracy = 정확히 예측한 수 / 전체 예측 수
- FP: False-Positive (잘못된 positive, 양성으로 잘 못 예측)
- FN: False-Negative (잘못된 negative, 음성으로 잘 못 예측)
logloss 구현
```python
def logloss(y, pred):
tot = 0
for label, p in zip(y, pred):
tot += -np.log(max(p[label - 1], 1e-15))
return tot / y.shape[0]``
'AI > Big data' 카테고리의 다른 글
| 영화 추천 - 높은 평균 평점 기준 (0) | 2022.03.21 |
|---|---|
| hyperparameter tuning (0) | 2022.03.19 |
| Titanic data analysis (0) | 2022.03.19 |
| Pandas DataFrame (0) | 2022.03.18 |
| Pandas Series (0) | 2022.03.18 |
