2022. 3. 6. 19:19ㆍAI/Deep learning
- 목차
SGD를 통해 gradient를 구할 때 반복적으로 같은 parameter(즉, weight)에 대해서 미분을 수행
이는 성능의 문제를 야기
layer가 계속 커지면서 편미분의 횟수가 quadratic 하게 증가함
중복되는 미분을 수행하지 않도록 즉, 동적 계획법을 적용하여 해결한 것이 바로 "역전파"
역전파
편미분의 중복을 없애고 효율적으로 수행
각 layer들의 여러 weight들의 최적화를 위해 미분값을 구함
결과를 고정하고, 입력을 최적화 (즉, 입력 벡터를 미분하여 학습)
이런 입력 𝜙벡터의 초기화를 통해 역으로 정해진 출력에 맞는 입력을 생성할 수 있음
미분의 체인룰 사용
f(g(x))' = f(g(x))' * g(x)'
x3 x4
----> g(x) -------> f(x) --------->
x g(x) f(g(x))
1 3 12
(x*3)*4
f(g(x))를 x로 미분하고자 함
d f(g(x))
------
g(x)
g(x)가 조금 증가할 경우 f(g(x))는 얼마나 증가하나
d g(x) f(x+t) - f(t)
------ = lim -------------
dx x
forward pass 1회와
backward pass 1회로
모든 편미분을 한번에 계산함
f1(x)
f2(f1(x))
f3(f2(f1(x)))
f4(f3(f2(f1(x)))) = output
f5...
output을 f5로 미분
backward pass
출력단부터 입력단까지의 미분 체인룰을 통한 분해
d out
g5 = --- = 2*f5
df5
g4 = d out d f5
----- = ---- * g5 = 2*f5
d f4 d f4
g3 = d out d f4
----- = ---- * g4 = 2*f5
d f3 d f3
....
즉,
d out d f5 d f4 d f1
----- * ---- * ---- * .... * ----
d f5 d f4 d f3 d v1
이기에,
d out
----- <- f3의 경우 - 이걸로 f3의 weight을 갱신
d f3
d out
----- <- 최종단의 경우 - 이걸로 v1의 weight을 갱신
d v1중간의 미분 결과를 재사용하겠다는 것
back으로 가면서
기존 계산 결과를 재사용하면서 앞단으로 가는 것
이렇게 하면 중복된 계산이 많이 없어짐
한번 계산된 것을 재사용 하는 것 임
GPU의 경우 100개의 data를 한번에 한번의 forward/backward pass로 GPU를 사용해 데이터 별로 갱신
weight 갱신의 경우 GPU를 써서 돌려도 결국 batch 인 경우 batch data 를 모두 각각 GPU 를 써서 돌린 이후 1회 weight 갱신임
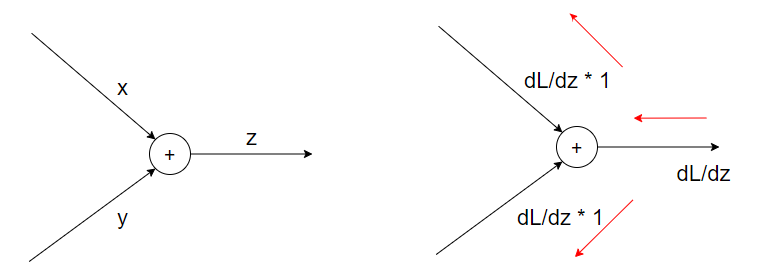
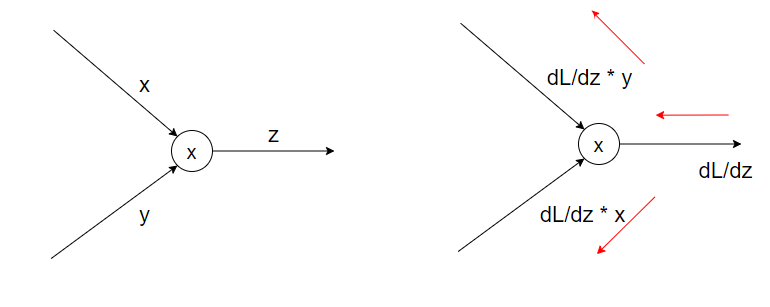
앞의 미분 결과에 현재의 변수에 대한 미분 결과를 곱하는 형태로 미분을 구할 수 있음
1 - (w ⋅ 𝜙(x)) 이 있다면,
입력 단계에서는 w ⋅ 𝜙(x) 에 대해서 w로 미분한 기울기 값을 적용하여 w를 갱신
다음 단계에서는 계산된
역전파
상류로부터 받은 값에 미분한 결과를 곱하여 하류로 전파
'AI > Deep learning' 카테고리의 다른 글
| Keras로 MF 구현 (0) | 2022.05.15 |
|---|---|
| user based CF, item based CF (0) | 2022.03.22 |
| Activation function(활성 함수) (0) | 2022.03.06 |
| RNN(Recurrent Neural Network) (0) | 2022.03.06 |
| seq2seq (0) | 2022.03.06 |

