2022. 5. 14. 18:37ㆍAI/Machine learning
- 목차
대용량 데이터에서 '중요한' 정보를 뽑아내고 의미있는 결과를 도출하는 절차를 '데이터 마이닝' 이라 한다.
혹은 데이터 안에서 자동으로 통계적 규칙이나 패턴을 찾는 것을 의미하기도 한다.
데이터 마이닝이 발전한 이유는 요즘 많은 테크 기업들이 적극적으로 도입하고 있는 '추천' 기술과 관련이 있다.
요즘과 같이 딥러닝을 이용한 추천 시스템 이전에는 머신 러닝 기법은 Factorialization Machine 등의 기법을 사용했으며 (Netflix), 그 이전에는 마켓-바스켓 모델이라던가, A-priori 알고리즘 등의 데이터 마이닝에서 다루는 알고리즘등이 사용되어 왔다.
Market-basket model
어떤 제품 i를 구입했을 시 j라는 제품도 함께 살지 안 살지에 대한 것을 예측하는 모델이다.
confidence와 interest라는 두 가지 주요 지표를 사용한다.
confidence(i -> j)는 i를 구입했을 시 j를 구입할 확률을 의미하며,
interest(i)는 i를 구입하고 j도 구입할 확률에서 j만 구입할 확률을 제외한 확률
즉, 정말 i도 구입하고 j도 구입한 확률을 의미한다.
추천 시스템에서는 위와 같은 고전적인 방법을 다루지는 않는다.
추천 시스템의 고전으로 다뤄지는 방법은 잘 알려진 content-based filtering과 collaborative filtering 기법이다.
Content-based filtering
사용자가 높은 평점을 내린 item 중에서 feature의 특징이 유사한 item들을 추천하는 방식이다.
즉, 이 방식은
1) 사용자가 어떤 item을 선택했던 정보를 기반으로 한다. (선택된 것이 없을 경우 추천할 수 없다. 이는 cold-start라 한다)
2) item간의 유사도를 정확히 계산할 수록 추천의 성능이 높아진다.
즉, item간의 유사도를 정밀히 계산할 수 있는 feature의 '추출'이 중요하다.
content-based filtering과 유사한 것이 바로 '검색'이다.
단순한 문서 검색의 경우 잘 알려진 TF-IDF 기법을 통해 가장 유사한 topic들을 찾아낸다.
content-based filtering에서는 item들의 feature를 선택하고 (1)
이 feature들의 가중치 벡터를 정의하고 (2)
이 벡터들 간의 유사도를 계산하여 (3)
유사성이 높은 item 들을 찾아낸다.
feture를 어떻게 뽑아 낼 것인가는 추천을 적용하고자 하는 field마다 다르다.
간단히 예를 들어보면, 영화의 추천을 할때 feature로 뽑을만한 것은
- genre
- actors
- directors
- release year
등이 될 것이다.
genre의 경우 이를 단 하나의 field로 genre를 정의하지 않고
genre 역시 하나의 벡터로 구성되도록 다양한 field를 정의해야 한다. (soft drama, action, romantic comedy, hillarious...)
그러나 장르다 유사하고, 배우가 유사한 정도를 가지고 추천하는 'content-based filtering'은 추천의 한계가 있다.
즉, 유사한 제품만 추천하고 미경험한 제품을 추천하지 못한다는 overfitting 문제가 존재한다.
그래서 보다 많이 사용되는 방식이 바로 collaborative filtering 방식이다.
Collaborative filtering
collaborative filtering은 item의 유사성을 기반으로 추천하는 것이 아니라, 여러 사용자 간의 유사성을 기반으로 추천하느 것이다. A라는 영화를 좋아하는 사람이 1이 B라는 영화를 좋아한다고 해보자. 이 때 2라는 사람도 A를 좋아한다면, B도 좋아할 지도 모른다는 것이 collaborative filtering 방식의 추천 방법이다.
collaborative filtering 방식에는 크게 두 가지 방식이 존재한다.
1) uer-user CF
나와 유사하게 item을 평점한 user를 찾아 그 user의 평점으로 나의 평점을 예측하는 방법이다.
다음과 같은 사용자들의 영화들에 대한 평점 데이터가 있다고 가정해보자.

위의 데이터에서 timestamp를 제외하고 movie_id와 user_id의 cross table을 만들어 보자.
| rating_matrix = x_train.pivot(index='user_id', columns='movie_id', values='rating') |
다음과 같은 table이 만들어진다.
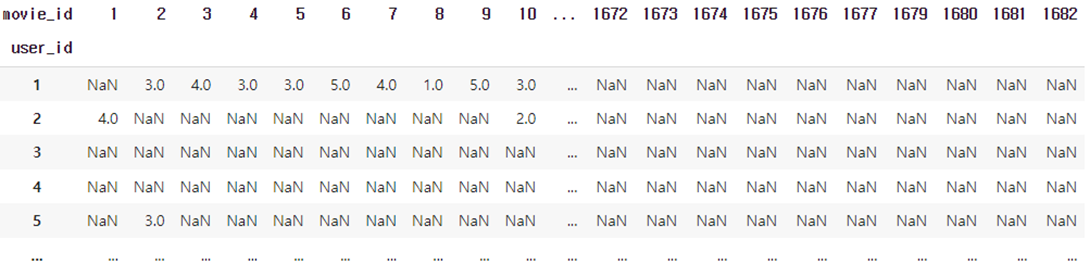
이제 각 행에는 각 user가 모든 영화에 대해 어떻게 평점을 내렸는지에 대한 값들이 저장되어 있다.
즉, 하나의 행은 한 user의 영화 평점에 대한 벡터이다.
이들 벡터의 유사성을 모든 user에 대해 계산하여 추천하는 것이다.
(대충 생각해도 N개의 user가 존재하고 M개의 item이 존재할 시, O(MN^2)의 시간이 소모된다.
각 user의 벡터의 유사도를 계산하는 방식에는 다음의 3가지 방식이 존재한다.
1) Jaccard similarity
교집합의 크기 / 합집합의 크기
평점 정보를 보지 않아 부정확
2) cosine similarity
세타 방향의 유사도
내각인 경우 유효
90도는 0 (관련 없음)
둔각인 경우 부정 (반대적 측면으로 유효)
3) Pearson correlation coefficient
평점에서 평균을 빼서 계산
cosine similarity와 유사하나, 평점에서 평균을 뺀 값을 사용함
Item-item CF
이번에는item을 user들이 socre 한 것이 feature 벡터가 된다.
user 별로 score가 비슷하게 매겨지는 item을 추천한다.
개개인만의 score를 보고 추천하는 것이 아니다.
CF의 장점
- 어떤 item에 대해서도 동작
- 평점 정보만 있으면 됨 (feature design의 과정이 필요 없음)
- 보통 가장 좋은 성능을 보여줌
CF의 단점
- cold-start
- sparsity
- 같은 item에 대해 평점을 내린 사용자를 찾기 어려움
- 벡터가 sparse 벡터임
cold-start 문제 피하기
사용자 정보 기반 추천
ex. 음악의 경우 좋아하는 장르, 가수 입력 등
'AI > Machine learning' 카테고리의 다른 글
| Surprise (0) | 2022.05.15 |
|---|---|
| Latent factor model: matrix factorization (0) | 2022.05.15 |
| CF model with visual information (0) | 2022.03.27 |
| 언어모델 (0) | 2022.03.13 |
| Matrix factorization 접근법 (0) | 2022.03.13 |


